


Apache Arrow Essentials - Part 2
Apache Arrow's Memory Model - Working with Columnar Data

In Part 1 of my Apache Arrow Essentials series I introduced the concept of Apache Arrow, highlighting its key features. We explored how Arrow serves as a development platform by providing a standardized columnar memory format. This standard format not only promotes language interoperability but also optimizes data operations for improved performance. I also explained what it means when we say that Apache Arrow is "in-memory" and why its columnar memory layout is considered a standard in the world of data analytics.
In Part 2, we will dive deeper into Apache Arrow's memory model. We'll take a closer look at its columnar layout, exploring how this design enhances memory efficiency compared to traditional row-based formats. By the end of this section, you'll gain a clearer understanding of why Apache Arrow's architecture can significantly boost your analytical workloads and how you can leverage it to maximize performance in your data projects.
This series is designed to provide a high-level overview of the standout features of Apache Arrow. If you're looking for a deeper dive, I highly recommend Matthew Topol's book, *In-Memory Analytics with Apache Arrow*, now available in its 2nd edition on Amazon. The first edition was a game-changer for me, sparking a two-year journey that ultimately inspired this series. Throughout these articles, I’ll be sharing diagrams from the book while expanding on certain topics that I believe could benefit from more straightforward explanations. My aim is to get you to the doorstep of understanding Apache Arrow—what you do next is entirely up to you.
I’m not sponsored or affiliated in any way to endorse this book—it’s simply the only comprehensive book available on Apache Arrow and a very good investment of your time.
Understanding columnar memory layout
Returning to our Papua New Guinea census data example—now that you’ve got the data, let’s analyze it. In my first article, I may have given the impression that only Apache Arrow loads data into memory, but that’s not the case. Most applications do this through a process known as serialization and deserialization. What sets Apache Arrow apart is the unique way it handles this process.
Serialization
Serialization is the process of converting data into a format that can be easily stored or transmitted. For instance, when you need to save data to a file, send it over a network, or pass it between different applications, it needs to be serialized. Common formats include JSON, CSV, or binary formats like Protocol Buffers or Apache Avro. This process typically involves converting the in-memory representation of data (e.g., objects in Python or rows in a database) into a byte stream that can be written to disk or sent across a network.
Deserialization
Deserialization is the reverse process—it converts the serialized byte stream back into the original data format that applications can work with. For example, when you receive data from a file or over the network, it arrives in a serialized format, and you need to deserialize it back into its original structure to perform any meaningful analysis or manipulation.
How Apache Arrow is Different
Most applications that handle data go through this cycle of serialization (to save or transmit data) and deserialization (to read it back into memory). However, these processes can be computationally expensive, especially when dealing with large datasets. Apache Arrow differentiates itself by using a standardized in-memory columnar format that eliminates the need for repeated serialization and deserialization.
Instead of converting data back and forth between formats, Arrow keeps it in a memory-efficient, columnar layout that can be directly accessed and processed by multiple systems and languages. This approach reduces overhead, speeds up data operations, and enables faster data sharing between different components of your data pipeline, making it especially useful for analytical workloads like the Papua New Guinea census data example we're exploring.
That was a bit wordy, so let's break it down with a simple example. Imagine we have census data that includes just a person's first name, age, gender, and birth year saved on a CSV file. This isn't a real dataset—just a simplified version for illustration purposes.
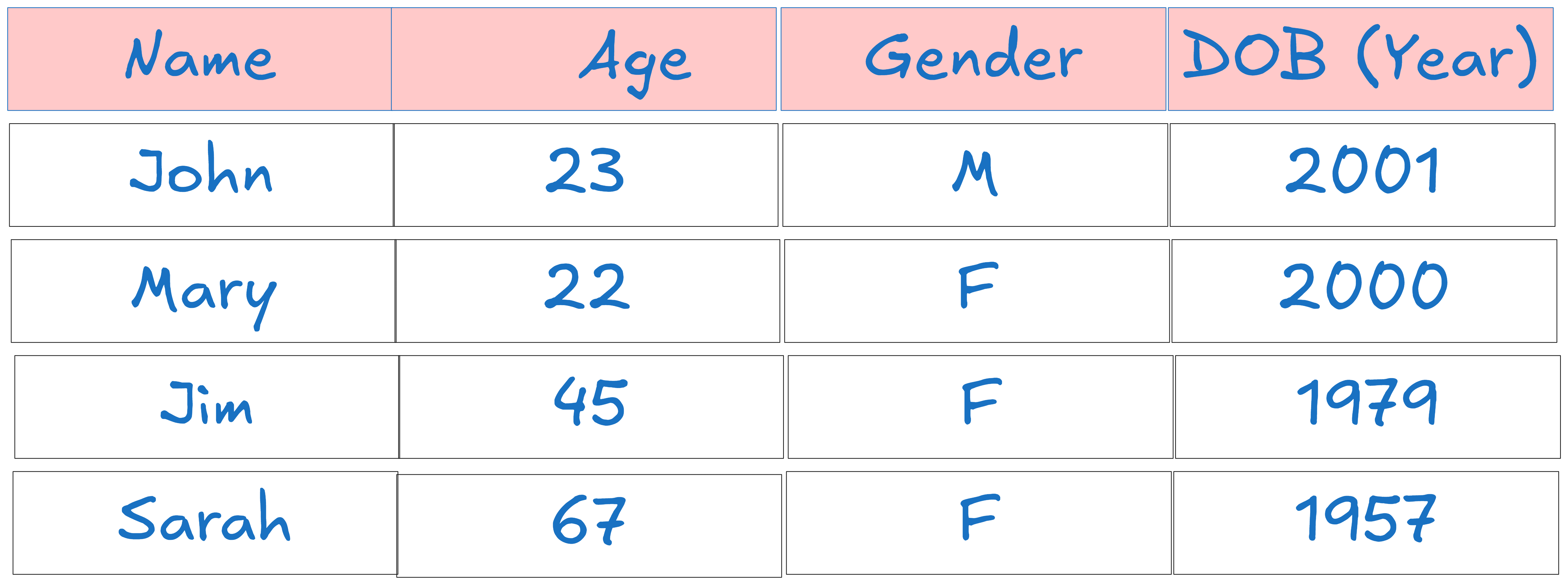
CSV is an on-disk file format designed primarily for storing data. Its main purpose is to keep data saved on disk in a simple, human-readable text format. However, when you open a CSV file in Excel or another application, it doesn't just display the data directly from disk—it has to convert it into a format that can be used in memory for analysis and manipulation. This is where the concepts of serialization and deserialization come into play.
Again!,serialization is the process of converting structured data into a storable format like CSV, while deserialization is the reverse process—reading that stored data and transforming it back into an in-memory representation that software like Excel can work with. When Excel opens a CSV file, it deserializes the data, loading it into its own internal, in-memory format, allowing you to interact with and analyze the data efficiently. This conversion step is crucial for bridging the gap between static data storage and dynamic data analysis.
Have you ever noticed that the larger a file is the slower Excel seems to be when your scrolling through the data? 😁 tried increasing memory?
Below is a very simple (very simple!) representation of how this would look in practice, I have included row oriented and column oriented memory buffer in deserialization so that you can see the difference. Really, if you look at it, in both cases the only thing that’s different is how the data is represented in memory.

Contigous Blocks of Memory
From the above diagram, you can start to see how Arrow’s use of a columnar memory layout lends itself well to analytics use cases, because having the data already “grouped” as columns allows operations to focus on specific fields without reading unnecessary data. These characteristics make Arrow ideal for analytical workloads that involve aggregation, filtering, and projection, all of which benefit from fast, column-focused processing.
Now, Arrow's columnar memory layout does not work in isolation; it still has to be implemented on physical memory somehow. Arrow achieves this through the use of buffers. Buffers are contiguous blocks of memory that store data for each column, organized in a way that adheres to Arrow's columnar format. Each buffer represents a specific aspect of a column, such as the actual values, null bitmaps (to track missing data), and offsets (for variable-length data like strings). These buffers are tightly packed and memory-aligned, enabling efficient access and manipulation.
At this juncture, I would like to remind the reader to not just think of Arrow as just a ‘program’; it’s more than that. Arrow is a specification that defines a standard for how columnar data should be stored and accessed in memory. This specification is language-agnostic and focuses on enabling interoperability, performance, and efficiency across different systems and programming languages. It sets out rules for memory layout, metadata, and data types, ensuring that any implementation adhering to the Arrow standard can share data seamlessly with others. In addition to being a specification, Arrow also provides robust implementations in various languages like Python (PyArrow), C++, Java, and more, making it both a framework for developers and a bridge between diverse data systems. This dual role as a specification and implementation is what makes Arrow so powerful and versatile.
Very wordy again! Lets give an example to summarize what was written above. Lets take the ‘Age’ column in our example table.
Lets assume Mary’s Age was missing, so instead of 22, that value is NULL. So our fixed 32-bit integer array looks like [23, UNF, 45, 67]


First we isolate the age column, since Arrow has a column oriented in-memory format we can think of each column as being in one contigous block of memory. Next, to demonstrate how Arrow handles missing (null) values Ive taken out Marry’s age value (22) so our final ‘memory array’ is 23,UNF,45,67, UNF being ‘undefined’.
The binary representation makes it more clear how each value in the buffer is stored as a 32-bit signed integer, 32 bits because each integer is represented using 4 bytes of 8 bits (4 x 8 = 32). For the purposes of our example I have zeroed the UNF value but since the Arrow format specification does not define anything, the data in a null slot could technically be anything.
The remaining bytes from 16 to 63 are used as padding so that the memory buffer has a total of 64 bytes, why do we pad the values? why not leave them out? Because padding data buffers to a multiple of 64 bytes is crucial for maximizing performance on modern x86 processors, such as those supporting Intel's AVX-512 SIMD instructions. This alignment enables efficient memory access and processing, as the hardware can load, store, and operate on 64-byte chunks in a single operation. Misaligned buffers could lead to additional overhead from unaligned memory access, reducing computational efficiency. By adhering to 64-byte boundaries, Apache Arrow ensures its data structures are optimized for parallel processing and high-performance analytics.
Validity Bitmap Buffer
The memory buffer that holds the 32-bit integer array in the previous example is what is called the value buffer .i.e. the memory buffer that actually holds the values. But there is another memory buffer that usually accompanies the value buffer which is called the validity bitmap buffer. In Apache Arrow, a validity bitmap buffer is a memory-efficient way to represent the presence or absence of values in a column or array. It's essentially a bit vector (bitmap) that tracks which elements in an array are valid (non-null) and which are null.
Now the reason why in the previous example I removed Mary’s age (22 years) from the ‘Age’ column was to show how Apache arrow represents null values in the value buffer but also I want to show how that plays into the validity bitmap buffer.

Look at the image above, here we have our 32-bit integer array and below it we have our validity bitmap buffer, where there is a value in the value buffer there is a corresponding 1 (yes/true) in the validity bitmap buffer and where there is a null value in the value buffer there is a corresponding 0 (no/false) in the validity bitmap buffer.
"The validity bitmap buffer uses a least-significant-bit-first representation, where the null status of the first element is indicated by the rightmost bit in the bitmap.”
Ok why do we need it? 🤔
The validity bitmap buffer provides an efficient mechanism for tracking null values, allowing quick null checks by examining a compact bitmap rather than scanning the entire value buffer.
Alright one last thing to learn and remember 🥱😴
The example above with the age values of our dummy table is an example of how Apache Arrow manages a fixed width value array in memory such as integers, floats or booleans. This is an array where each element occupies a consistent, predetermined amount of memory. This is different from variable-length arrays where elements can have different sizes.
We will cover examples of fixed and variable width value arrays in the course of this series.
Very nice post again :)
I still have the same doubt. You say “eliminates the need for repeated serializations and deserializations”. But as I understand it you just use a different memory representation which seems faster for data exchange, but you also have to serialize Buffers into Byte Streams or am I wrong?